Apache Kafka is a practical choice to a standard messaging system. It began as an inner system developed by Linkedin to take care of 1.4 trillion day-to-day messages. Nevertheless, today it’s an open-source data streaming system that can meet a series of business requirements.
reference : 아파치카프카 engkimbs
What is Apache Kafka?
Apache Kafka is an open information shop made to procedure as well as ingest streaming data in real-time. Streaming information is constantly produced by numerous data sources that usually send data records all at once. Consequently, a streaming platform must cope with this constant circulation of information and also process the information incrementally and in a series.
Apache Kafka has three main objectives for its users: 아파치카프카 engkimbs
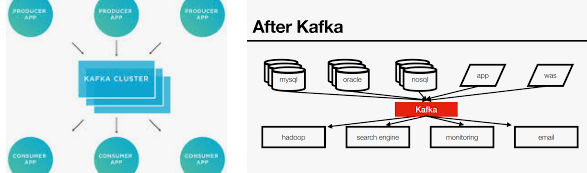
What is the procedure behind the Kafka feature?
Apache Kafka(아파치카프카 engkimbs) incorporates 2 messaging designs that are queuing and also publish-subscribe, providing the main benefits of both to users. Queuing enables the handling of information to spread out across numerous circumstances of the customer, making it incredibly versatile. Yet standard lines aren’t multi-subscriber. The method of publishing-subscribe is multi-subscriber. However, considering that every message mosts likely to each customer, it can not spread out job throughout different worker procedures. Apache Kafka utilizes the separated log version to connect both of these remedies. Logs are an ordered series of records. The logs are split right into partitions or sectors representing various customers. There may be lots of clients to a comparable subject, and each one is appointed a different department that allows for better ability. Additionally, Kafka’s model allows replayability, which allows several independent applications that review information streams to run separately at their own speed.
The advantages of Apache Kafka’s method
Scalable.
Kafka’s partitioned log model makes it possible for details to be spread over several servers, making it scalable beyond what could be fit on one server.
Rapid.
Kafka is an information stream decoupler that has really low latency. So, This makes it highly reliable.
Durable.
Dividers are replicated and also distributed over a number of web servers. Additionally, the data is written to the disk. This secures against servers’ failing, which makes the information durable and trustworthy.
Apache Kafka has three main objectives for its users
Produce as well as sign up for streams of records
Efficiently save streams of records in the order that documents were produced.
Refine documents right into streams in real-time
Apache afka is used mainly to create real-time streaming information pipelines in addition to applications that can adapt to a stream of information. It mixes storage space, messaging and also stream processing to enable the storage and also analysis of real-time as well as historical data.
Why would certainly you wish to use Apache Kafka?
Kafka can create real-time streaming pipes for data and applications that stream in real-time. Information pipelines are trusted in handling and transferring the data between one tool and also the next, as well as a streaming app can be referred to as an app that eats a stream of information. For instance, if you want to establish an information pipe that takes the information from individual task to keep track of exactly how users search your website in real-time. Apache Kafka would certainly be used to store as well as consume streaming information and offer readings to the applications that run your information pipeline. Kafka is also frequently used as a message broker that functions as a facilities that handles and also facilitates communication between 2 applications.